在片上缓存场景下,将 OPT 缓存替换算法应用于过去的访问请求,从中学习以指导未来的缓存替换决策。
“If past behavior is a good predictor of future behavior, then our replacement policy will approach the behavior of Belady’s algorithm.“
Hawkeye
overview

OPTgen 使用过去的访问记录,模拟 OPT 行为以产生训练数据;
Hawkeye Predictor 对新插入对象进行分类:缓存友好和缓存厌恶。
OPTgen
三个定义
- usage interval:从对某数据的引用 X 开始,到下次对相同数据的引用 X’ 的长度;
- liveness interval:在 OPT 策略下,缓存行在缓存中的驻留时间段;
- occupancy vector:记录每个时刻使用的缓存容量。
如果在 X 的 usage interval 过程中,任何时刻其它对象的 liveness intervals 重叠数目达到了缓存容量,则在下一次的引用 X’ 时,该数据缺失;否则,该数据命中。(对于 Belady 的理解,最直观的是在缓存驱逐决策过程中,驱逐从此时开始,缓存空间中前向重用距离最大的对象,而这里给了一个全新的视角,某个对象引用的 usage interval 过程中,其它对象的 liveness intervals 最大重叠数达到了缓存容量,这意味着在此最大重叠时刻,该对象的前向重用距离就已经是最大的了,这从缓存驱逐决策的视角转化为了对象下次重用时是否命中的判断)。
对于下图所示,X 第一次引用时的 usage interval 为 6,重用距离为 3,但是,在 liveness interval 过程中,其它对象的 liveness intervals 最大重叠数仅为 1,因此,在第一次引用时,OPT 的判断为 X 下次引用将命中。
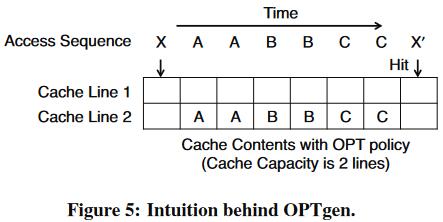
对于下面的访问 trace,OPT 策略使得缓存命中数为 4(实际上这是带准入的 OPT——当缓存容量满时,如若当前缺失对象的前向重用距离大于缓存中的所有对象,则不会准入,这比不关心准入的一般 OPT 命中率更高),其中,occupancy vector 的使用方式如下
- 最近引用的条目对应值为 0;(如果不考虑准入,则条目初始值为 1)
- 某对象的首次引用不会对 occupancy vector 的其他值造成影响,这反映出 OPT 只能基于对象的下次重用做出判断;
- 如果对象不是首次引用,OPTgen 将检查该对象对应 usage interval 过程中是否每个引用在 occupancy vector 中的值(等于 liveness intervals 重叠数)都小于缓存容量。如果是,则 OPT 在该对象上次引用时会将其加入缓存,此次访问命中,并且将 usage interval 过程中每个引用在 occupancy vector 中的值加 1;否则,此次访问缺失,无需更新其它引用在 occupancy vector 的值。

Hawkeye Predictor
“为何可以做预测” 基于这样一个事实:给定执行 load 命令的 PC,OPT 所做出的决策是相似的。文中提到,90.4% 的 load PC,在 OPT 看来有相同的缓存行为(缓存友好和缓存厌恶)。
文中提到,预测器有 8K 个条目,并使用 13-bit 的 hashed PC 进行索引,每个条目有一个 3-bit 计数器。如果 OPTgen 确定 X 在 OPT 策略下将是缓存命中,则增大上次访问 X 的 PC 对应条目的计数器,否则,减小计数器。
对于每次访问,预测器都通过当前的 load 指令 PC 进行索引,对应条目的 3-bit 计数器的高位标识其加载的数据是否缓存友好。
Replacement
在缓存替换时,Hawkeye 总体目标是先驱逐缓存厌恶对象,如果没有,则驱逐最久没有访问的缓存友好行(LRU),并减小其在预测器中的对应计数器。
进一步,作者将 Hawkeye 与 RRIP 结合,使用一个 3-bit 的计数器来标志驱逐优先级,具体做法是
- RRIP 计数器值越大,驱逐优先级越高;
- 在每次缓存访问时,Hawkeye 也测其生成一个二进制预测来指示该对象是否缓存友好,如果缓存友好,则赋予其 RRIP=0,同时,如果该对象不在缓存,还会增加其它 RRIP<6 的缓存对象的 RRIP 计数器(有点像 CLOCK);如果缓存厌恶,则赋予其 RRIP=7;
- 在缓存替换时,任何 RRIP=7(缓存厌恶)对象都会被选为驱逐候选者,而如果没有,则驱逐 RRIP 值最大的对象(LRU)。
以上确保了缓存厌恶对象会首先被驱逐(因为缓存友好对象的 RRIP 计数器最多增长到6)。
与 LRB 的异同
相同点
- Hawkeye 使用了 8X 缓存容量的时间窗口,LRB 使用了 2X 缓存容量的时间窗口,它们本质上都是希望从过去的时间窗口内探寻对象的缓存行为;
- 在进行驱逐决策时,Hawkeye 驱逐 RRIP 值最大的对象,该值是否为7标识了是否为缓存厌恶,小于7时,其大小则反映了对象的新近度;LRB 驱逐缓存对象中重用距离预测值最大的对象。
不同点
- Hawkeye 将 OPT 的决策看成一个二分类问题,并使用精彩的 liveness intervals 重叠数来非常准确地模拟出了 OPT 的行为,考虑了前向重用距离和缓存的需求(重叠数);LRB 将 OPT 决策看成一个回归问题,在时间窗口中简单地使用引用距离来作为标签进行训练;
- Hawkeye 应用于片上缓存,特征仅为加载指令的 PC 值,标签为在 OPT 策略下是否缓存命中;LRB 应用于 CDN 缓存,特征非常多,包括指数衰减新近度、频率、对象大小等等,标签为引用距离,而对于引用距离大于时间窗口(2X 缓存大小)的对象,引用距离即 2X 缓存大小。
收获
对于学习缓存,Hawkeye 和 LRB 这两篇不同应用场景下的缓存替换经典工作揭示了学习缓存过程中非常重要的几个问题
- 如何建模缓存问题?(这两个工作都是缓存替换,因此这里就是建模缓存替换问题,它们都是将问题建模成从 OPT 算法中学习驱逐的对应关系,Hawkeye 驱逐过去在 OPT 策略下不会缓存命中的对象,LRB 驱逐过去在 OPT 策略下引用距离过大的对象)
- 如何获取训练数据?(使用和缓存大小长度相关的时间窗口捕获历史 trace)
- 特征和标签是什么?(PC,OPT 策略下是否缓存命中)以及(新近度、频率、对象大小等特征,重用距离)
- 如何决定驱逐对象?(使用预测器对缓存对象进行预测,驱逐优先级最高的对象,对于缓存替换,这一步开销太大了)